#kubernetes #scheduler
# Scheduler in Kubernetes
The kube-scheduler is responsible for **scheduling Kubernetes pods on worker nodes**.
When you deploy a pod, you specify the pod requirements such as CPU, memory, affinity, taints or tolerations, priority, persistent volumes (PV), etc.
The scheduler’s primary task is to identify the create request and choose the best node for a pod that satisfies the requirements.
## Scheduling Workflow
The following image shows a high-level overview of **how the scheduling works**.
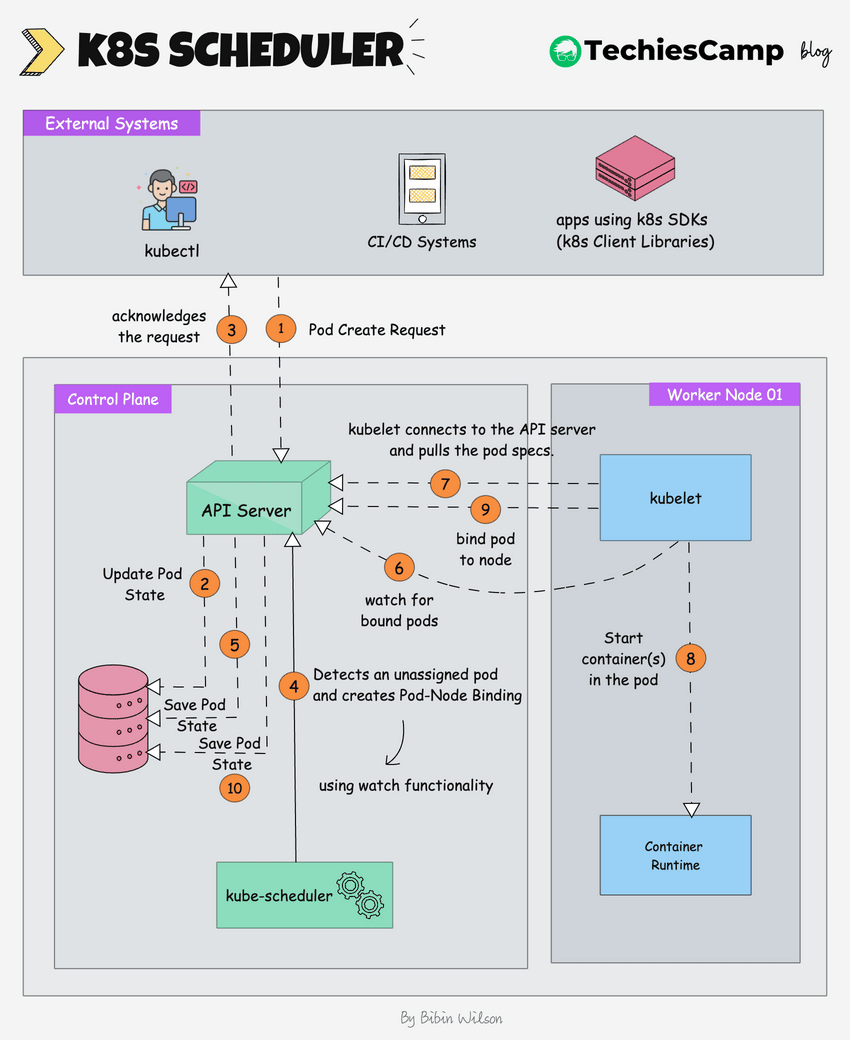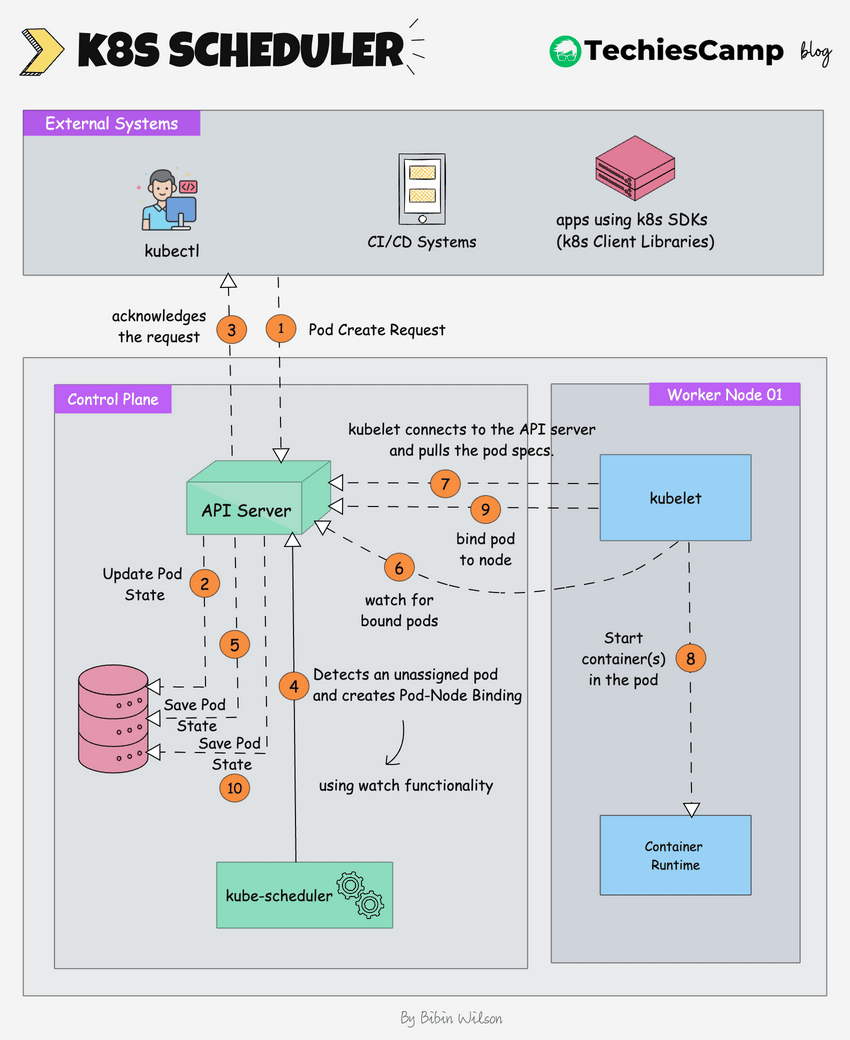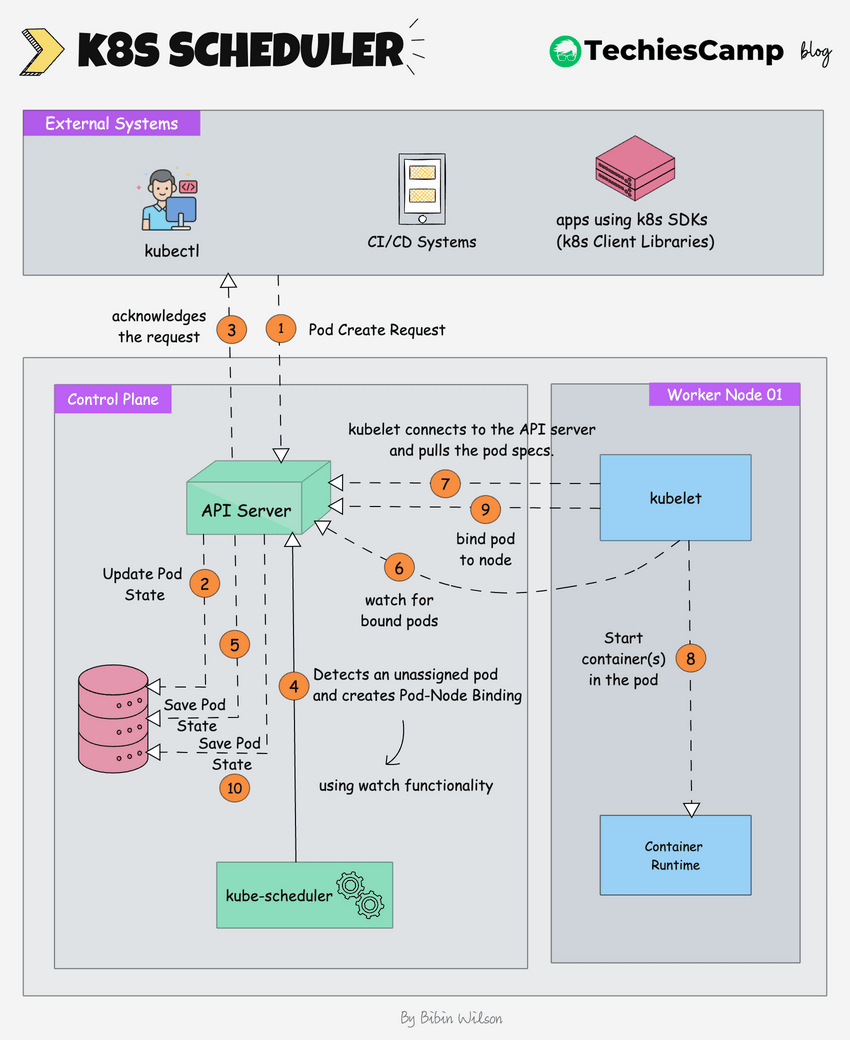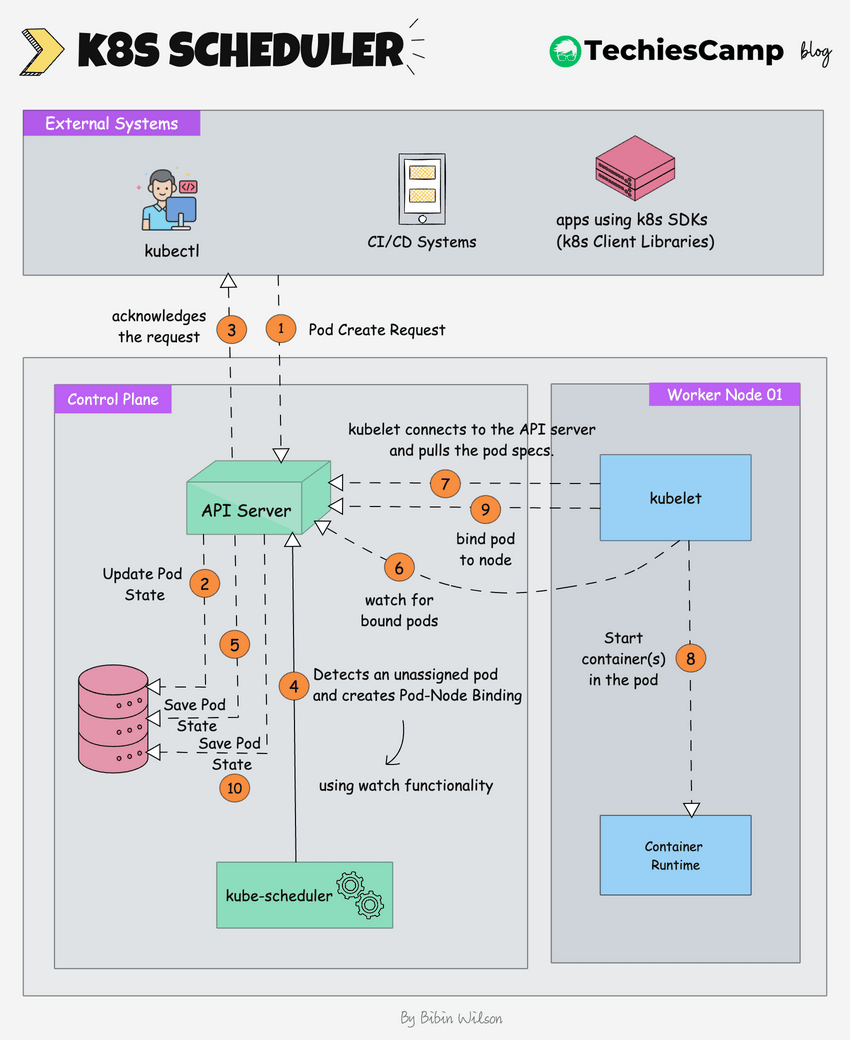
1. **Pod Create Request:** The process begins when an external system (like kubectl or a CI/CD system) sends a request to create a new pod.
2. The **kube-api server** receives this request and saves the pod state to [etcd](https://blog.techiescamp.com/docs/understanding-etcd/), the cluster's distributed key-value store.
3. The api server sends an acknowledgment back to the external system.
4. The **Kubernetes scheduler**, which is constantly watching for unassigned pods (using watch functionality), notices the new pod.
5. The **scheduler** decides which node the pod should run on based on the pod's requirements (e.g., CPU, memory, affinity/anti-affinity rules) and creates a **pod-node binding**. It informs the **API server** of this binding decision.
6. The **scheduler** updates the pod’s state in **etcd** (via the API server), marking it as "scheduled" with the node it is assigned to.
7. The **kubelet** on the selected worker node, which is constantly watching for new pod assignments (using watch functionality), detects the newly assigned pod.
8. The **kubelet** pulls the pod data from the **API server**. This data includes details like the container images, volumes, and networking configuration that need to be set up.
9. The kubelet instructs the container runtime (e.g., Docker, CRI-O) to start the container(s) for the pod.
10. The kubelet informs the api server that the pod is now bound to the node.
11. The api server updates the final pod state in etcd.The **API server** updates the final pod state in **etcd**, ensuring that the current state is accurately reflected in the cluster's database.
# How the Kubernetes Scheduler Chooses a Node?
In a Kubernetes cluster, there will be more than one worker node. So how does the scheduler select the node out of all worker nodes?
Th scheduler typically has two main phases:
1. Scheduling cycle
2. Binding cycle
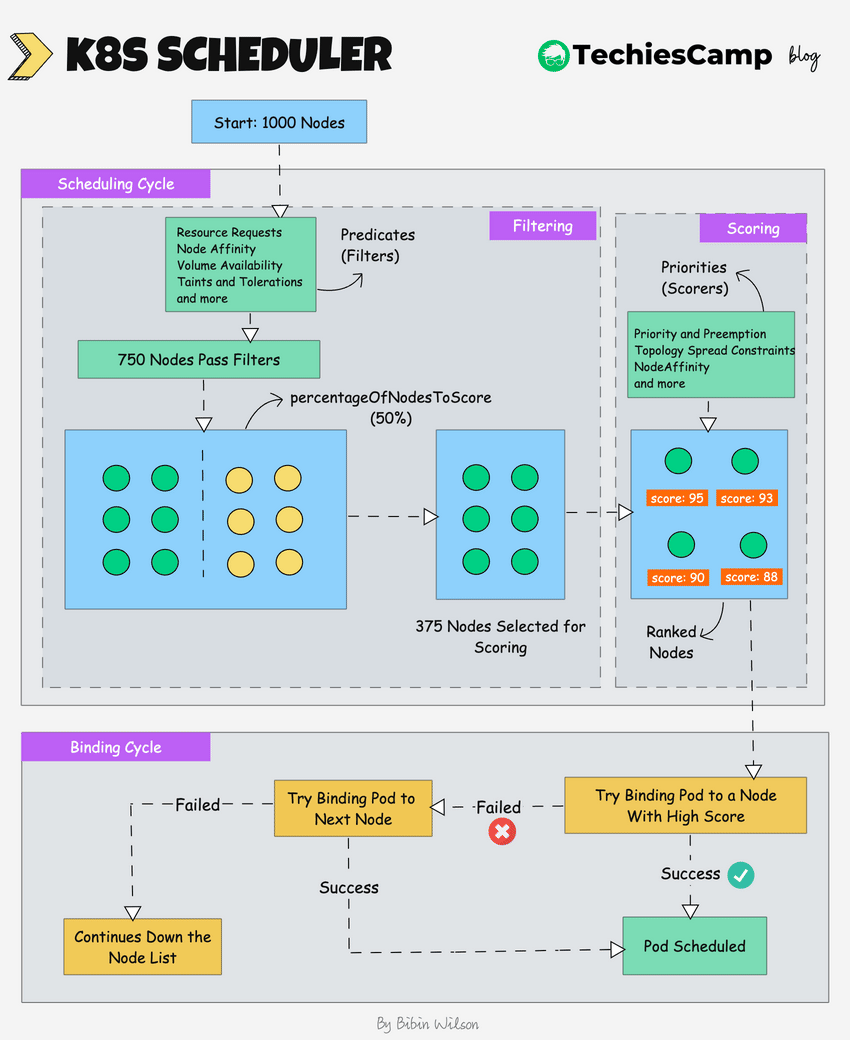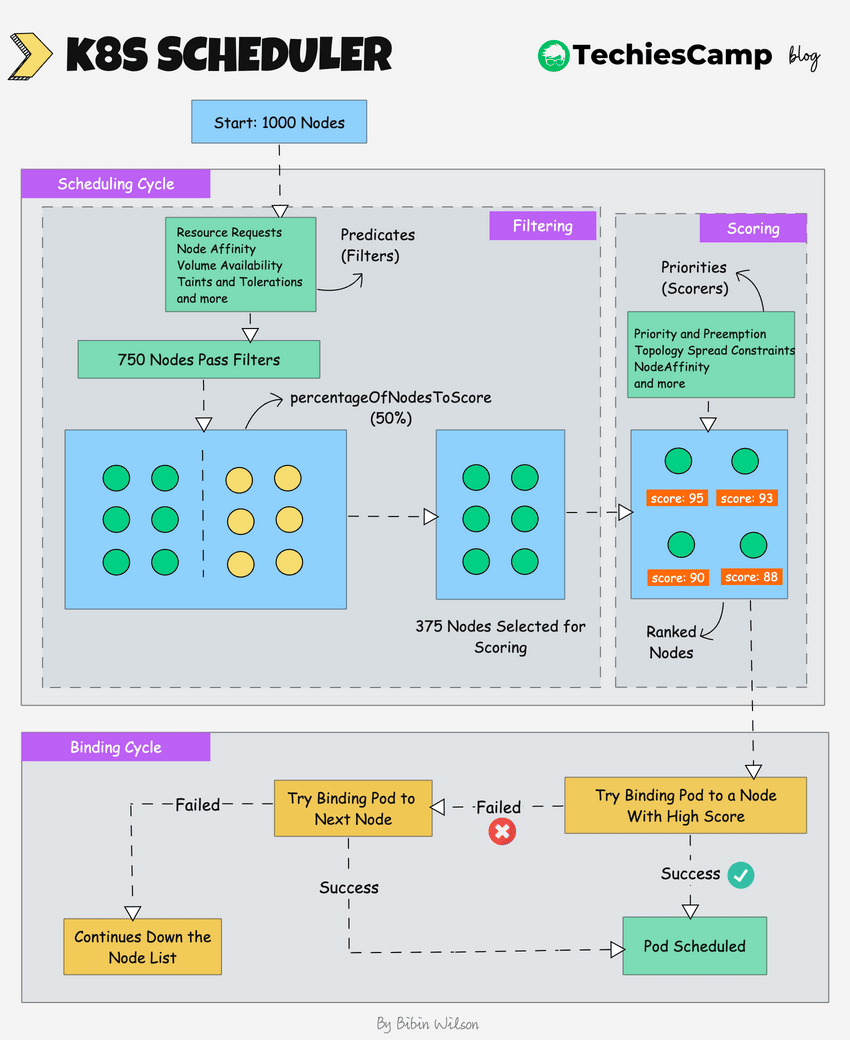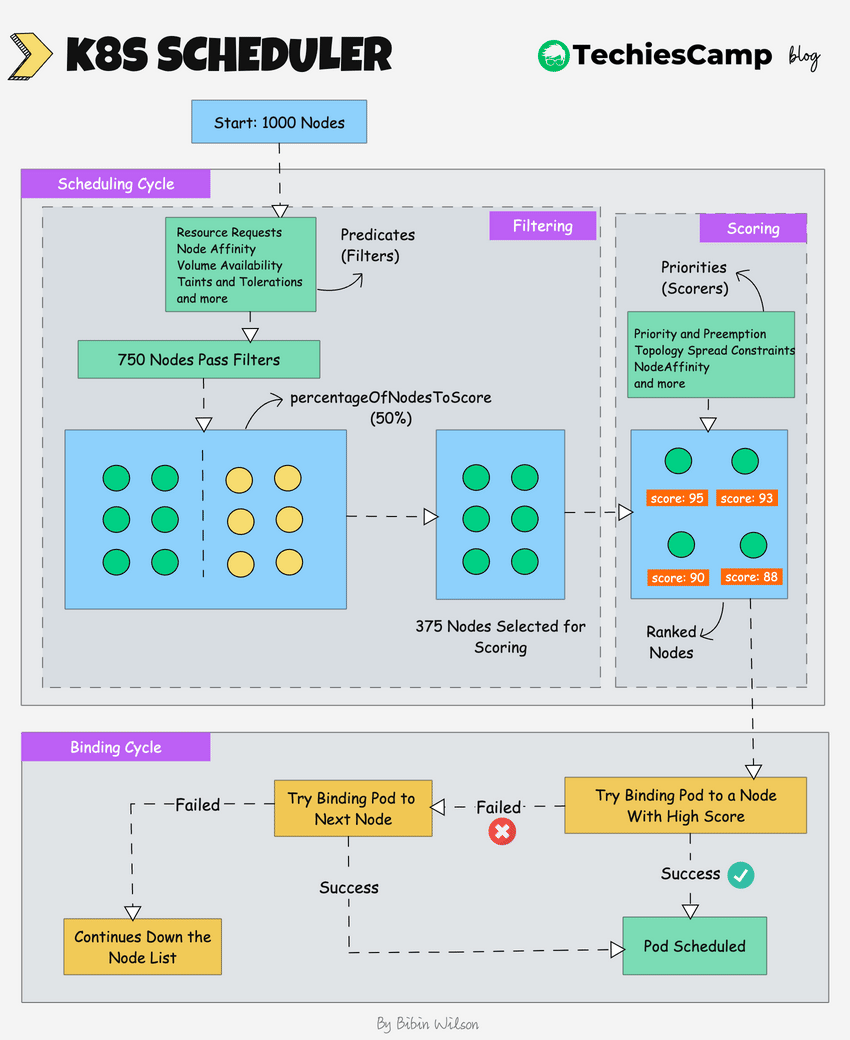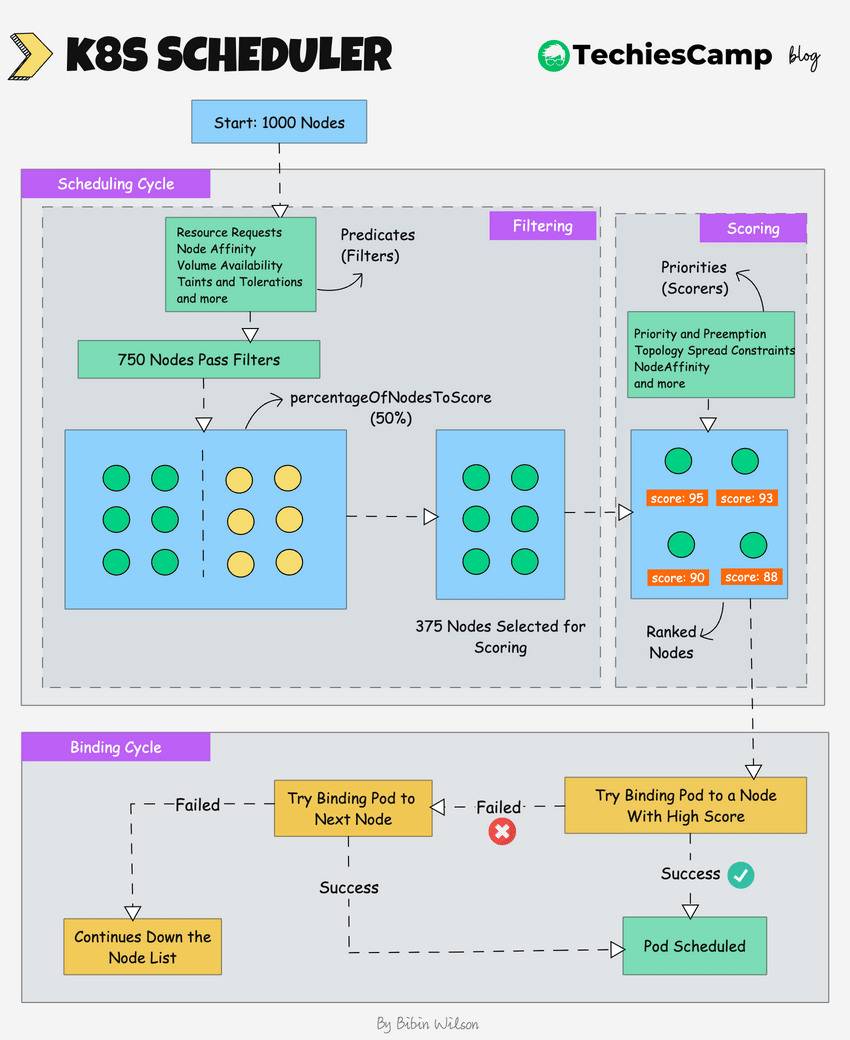
## Scheduling cycle
In this cycle, to choose the best node, the Kube-scheduler uses **filtering and scoring** operations.
### Filterning
In **filtering**, the scheduler finds the best-suited nodes where the pod can be scheduled.
It involves narrowing down the list of nodes to only those that **meet the requirements** specified by the pod's configuration. Essentially, it filters out nodes that are not suitable for running a particular pod.
For example, if there are five worker **nodes with resource availability** to run the pod, it selects all five nodes.
So how does Kubernetes know which nodes are eligible for running a pod?
Kubernetes uses **predicates** (commonly referred to as **filters**) to determine node eligibility. These filters evaluate various factors, such as:
1. **Resource Requests:** Ensures the node has sufficient CPU and memory resources for the pod.
2. **Node Affinity:** Checks whether the pod has specific rules about which nodes it should or should not run on.
3. **Taints:** Ensures that only pods with matching tolerations can run on nodes with specific taints.
4. **Volume Availability:** Ensures that the required storage volumes are available on the node.
If there are no nodes, then the pod is unschedulable and moved to the scheduling queue.
If it is a large cluster, let’s say `100` worker nodes, and the scheduler **doesn’t iterate** over all the nodes.
There is a scheduler configuration parameter called `**percentageOfNodesToScore**` (values between `0` and `100`). This parameter determines the percentage of nodes that will be evaluated during the scoring phase.
The default `percentageOfNodesToScore` varies based on cluster size, ranging from `50%` for small clusters to `5%` for very large clusters.
For clusters between `100` and `5000` nodes, the percentage **scales linearly** between 50% and 10%.
For Example, if the cluster size is 𝟱𝟬𝟬 𝗻𝗼𝗱𝗲𝘀 and the value of this flag is 𝟯𝟬, it tries to iterate over 𝟯𝟬% 𝗼𝗳 𝗻𝗼𝗱𝗲𝘀 in a round-robin fashion. Then scheduler stops finding further feasible nodes once it finds **150 feasible ones.**
If the worker nodes are spread across multiple zones, then the scheduler iterates over nodes in different zones.
For very large clusters the default **`percentageOfNodesToScore`** is 5%.
Also, Regardless of `percentageOfNodesToScore` settings, The scheduler will not stop looking for feasible nodes until it has found at least this minimum number.
So, even if the percentage of nodes to score is set to a low number, The scheduler will keep searching until it has found the `𝗺𝗶𝗻𝗙𝗲𝗮𝘀𝗶𝗯𝗹𝗲𝗡𝗼𝗱𝗲𝘀𝗧𝗼𝗙𝗶𝗻𝗱` number of feasible nodes.
### Scoring
In the **scoring phase**, the scheduler ranks the nodes by assigning a score to the filtered worker nodes.
Kubernetes uses **Priorities** (also known as **Scorers**) to score the nodes. These priorities are implemented through various scheduling plugins. Examples include:
1. Pod Priority: Higher-priority pods can influence node selection by affecting the scoring process.
2. Pod Topology Spread: Ensures that pods are spread across different topology domains (like zones or nodes) to avoid concentrating too many pods in one area.
The scheduler assigns scores to the nodes by calling multiple scheduling plugins. Each plugin evaluates the nodes based on specific criteria and contributes to the final score.
Finally, the worker node with the highest rank will be selected for scheduling the pod. If all the nodes have the same rank, a node will be selected at random.
Once the node is selected, the scheduler creates a binding event in the API server. Meaning an event to bind a pod and node.
## Binding cycle
This phase occurs after the filtering and scoring. The scheduler attempts to bind the pod to the highest-scoring node.
If binding fails, the scheduler typically moves to the next highest-scoring node.
## Summary
Here is shat you need to know about a scheduler.
1. It is a controller that listens to pod creation events in the API server.
2. The scheduler has two phases. **Scheduling cycle** and the **Binding cycle**. Together it is called the scheduling context. The scheduling cycle selects a worker node and the binding cycle applies that change to the cluster.
3. The scheduler always places the high-priority pods ahead of the low-priority pods for scheduling. Also, in some cases, after the pod starts running in the selected node, the pod might get evicted or moved to other nodes. If you want to understand more, read the [Kubernetes pod priority guide](https://devopscube.com/pod-priorityclass-preemption/?ref=blog.techiescamp.com)
[source](https://blog.techiescamp.com/)